

Mục tiêu:
Bài viết này nhằm cung cấp cái nhìn hệ thống và thực tế về cách triển khai streaming pattern phổ biến bằng Apache Spark Structured Streaming, kết hợp với các công nghệ phụ trợ như MariaDB, Redis, và Kafka. Đây là nền tảng để xây dựng các hệ thống xử lý dữ liệu thời gian thực trong các lĩnh vực như thương mại điện tử, chăm sóc sức khỏe, và giám sát hệ thống.
⚙️ Tiền đề & Công cụ sử dụng
- Apache Spark: Công cụ xử lý dữ liệu lớn với khả năng mở rộng mạnh mẽ.
- Structured Streaming: API cấp cao của Spark để xử lý luồng dữ liệu như một bảng động.
- MariaDB / Redis: Các hệ thống lưu trữ đầu-cuối (data sinks).
- Apache Kafka: Hàng đợi sự kiện dùng cho ingestion.
📘 Thuật ngữ trong hệ thống Streaming
| Thuật ngữ | Định nghĩa |
|---|---|
| Data ingestion | Quá trình thu thập dữ liệu từ các nguồn khác nhau (ví dụ: Kafka, API, file system) và đưa vào hệ thống lưu trữ hoặc xử lý trung tâm như Spark. |
| Data marshalling | Biến đổi cấu trúc dữ liệu trong bộ nhớ thành định dạng phù hợp để truyền tải hoặc lưu trữ (ví dụ: từ Object → JSON/XML). |
| Data sink | Điểm đến cuối cùng của dữ liệu, ví dụ như cơ sở dữ liệu, hệ thống lưu trữ tạm thời, dashboard. |
🌊 Đặc điểm của mô hình xử lý luồng dữ liệu (Streaming)
- Dữ liệu không giới hạn (unbounded datasets): Không thể biết trước lượng dữ liệu sắp tới.
- Từng bản ghi một (record-by-record): Mỗi sự kiện đến sẽ được xử lý riêng biệt.
- Xử lý thời gian thực (real-time): Dữ liệu được thu thập → xử lý → phân tích → hiển thị gần như tức thì.
- Độ trễ thấp (low-latency): Insight được tạo gần thời điểm sự kiện phát sinh.
🔧 Apache Spark Structured Streaming: Nền tảng xử lý mạnh mẽ
✅ Khả năng chính
- Hỗ trợ xử lý micro-batch (độ trễ < 100ms)
- Tích hợp trực tiếp với các nguồn/sink như Kafka, S3, Redshift, MongoDB
- Quản lý trạng thái: cần thiết cho các phép join hoặc aggregation có tính nhớ
- Hỗ trợ event-time processing
- Tích hợp MLlib cho học máy thời gian thực
🧪 APIs
- DStream API (cũ): Xây dựng trên RDDs, phù hợp cho các phép toán map-reduce.
- Structured Streaming API (mới): Dựa trên Spark SQL Engine, xử lý như DataFrame/Dataset → dễ mở rộng và tương thích với hệ sinh thái Spark hiện đại.
📊 Streaming Analytics là gì?
Streaming Analytics là kỹ thuật phân tích dữ liệu ngay khi dữ liệu được tạo ra, sau đó công bố insight tức thì cho hệ thống khác sử dụng: dashboard, cảnh báo, tự động hóa hành động.
Một số ứng dụng điển hình:
- Thương mại điện tử: Phân tích đơn hàng, hành vi người dùng trong thời gian thực
- Y tế: Thu thập chỉ số sinh tồn từ thiết bị y tế, phân tích theo thời gian
- Giám sát hệ thống: Theo dõi log lỗi, cảnh báo quá tải theo ngưỡng định nghĩa
📐 Mô hình xử lý dữ liệu Streaming
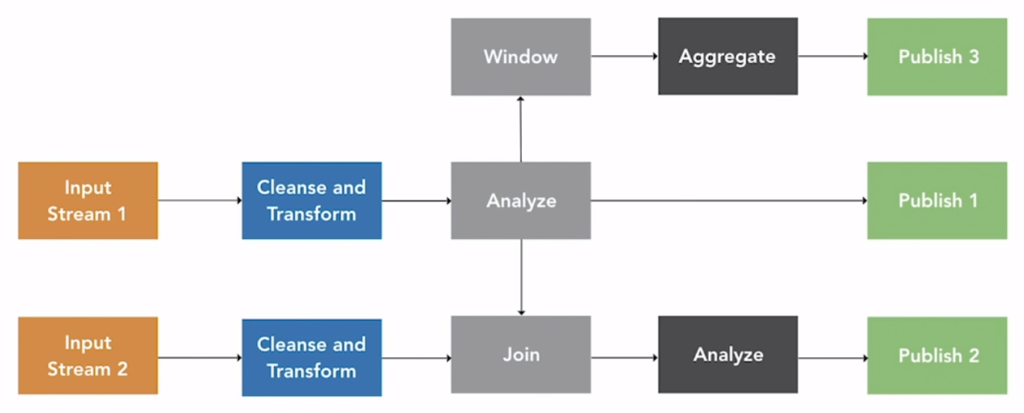
Diễn giải quy trình:
- Input stream (Kafka, IoT device, API) → Đưa vào Spark.
- Làm sạch và chuyển đổi: chuẩn hóa format, validate dữ liệu.
- Phân tích từng record: ứng dụng business logic.
- Kết quả được đẩy sang output stream (DB, cache, dashboard).
- Windowing: Áp dụng cửa sổ thời gian (ví dụ: mỗi 5 giây) để tổng hợp insight.
- Join đa luồng: Có thể kết hợp nhiều input stream để tạo insight phức hợp.
💡 Ví dụ 1 – Phân tích đơn hàng theo thời gian thực
- Mỗi đơn hàng gửi vào Kafka với nội dung:
{product_id, price, quantity} - Spark Streaming nhận dữ liệu và tính tổng
price * quantity - Mỗi 5 giây cập nhật tổng doanh thu theo loại sản phẩm vào Redis
scalaCopyEditval rawOrders = spark.readStream.format("kafka").option(...).load()
val parsed = rawOrders.selectExpr("CAST(value AS STRING)").as[String]
.map(parseOrder) // hàm parse từ JSON → case class
val result = parsed
.withWatermark("eventTime", "1 minute")
.groupBy(window($"eventTime", "5 seconds"), $"productId")
.agg(sum($"price" * $"quantity").alias("totalRevenue"))
🚨 Ví dụ 2 – Cảnh báo theo ngưỡng
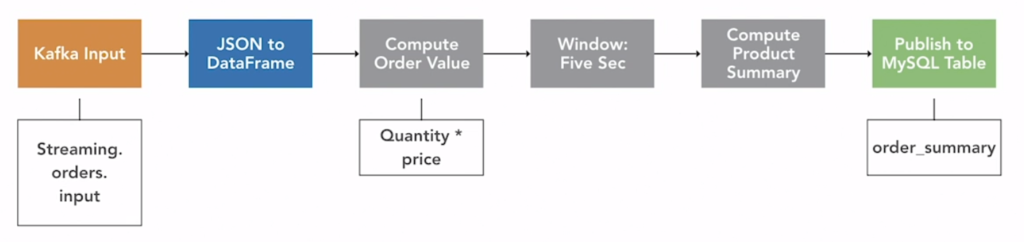
- Kafka topic chứa log hệ thống, dạng CSV:
timestamp,error_level,message - Spark Streaming đọc dòng mới và đếm số lỗi theo cấp độ mỗi phút
- Nếu số lỗi cấp “CRITICAL” > 10 → sinh cảnh báo
scalaCopyEditval errors = logs.filter($"error_level" === "CRITICAL")
val alertCounts = errors
.groupBy(window($"timestamp", "1 minute"))
.count()
.filter($"count" > 10)
✅ Tổng kết
| Yếu tố | Structured Streaming |
|---|---|
| Xử lý | Gần như real-time (micro-batch) |
| API | Dựa trên DataFrame/Dataset |
| Mở rộng | Rất tốt (hàng trăm node) |
| Dễ tích hợp | Kafka, DB, MLlib, cloud storage |
🎓 Gợi ý học tiếp
- Structured Streaming Programming Guide – Apache Spark
- Kafka + Spark Streaming integration patterns
- Tìm hiểu
stateful stream processing,watermark,windowed join,exactly-once guarantee.
Để lại một bình luận
Bạn phải đăng nhập để gửi bình luận.