
📘 Tư tưởng chủ đạo: Wittgenstein nói: “The limits of my language mean the limits of my world”. Trong hệ thống dữ liệu, mô hình dữ liệu chính là “ngôn ngữ” mô tả thế giới đó. Việc chọn mô hình nào sẽ ảnh hưởng lớn đến cách ta tư duy, thiết kế và tối ưu hệ thống.
🧱 Các lớp trừu tượng trong hệ thống dữ liệu
Mỗi lớp trừu tượng dữ liệu đại diện cho một cấp độ biểu diễn khác nhau:
- 🧠 Tầng ứng dụng: dùng object, struct, API để mô hình hóa thế giới thật.
- 🗃️ Tầng lưu trữ: dùng các mô hình phổ biến như relational, document (JSON/XML), graph, event log, dataframe.
- 💾 Tầng máy: biểu diễn dưới dạng byte trong RAM, trên disk, network stream.
- ⚡ Tầng phần cứng: ánh xạ byte thành dòng điện, ánh sáng, từ trường…
Mỗi tầng “ẩn đi” độ phức tạp của tầng dưới, giúp các nhóm kỹ sư có thể làm việc độc lập hiệu quả.
🧮 So sánh các mô hình dữ liệu chính
| Mô hình | Mạnh khi… | Yếu khi… |
|---|---|---|
| Relational | Dữ liệu có cấu trúc rõ ràng, cần join nhiều bảng | Không phù hợp dữ liệu tree/phức tạp không join được |
| Document | Dữ liệu tree, one-to-few, thường lấy cả document cùng lúc | Thiếu join, khó update một phần nhỏ |
| Graph | Nhiều quan hệ nhiều-nhiều, cần truy vấn qua nhiều bước (hop) | Không phù hợp cho dữ liệu transactional |
| Event log | Tập trung ghi (append-only), cần audit, CQRS, tracking lịch sử | Khó tìm trạng thái hiện tại, cần build thêm materialized view |
| Dataframe | Phân tích số liệu lớn, ML, feature engineering | Không phù hợp cho truy vấn transactional realtime |
💡 Không có mô hình nào tốt nhất cho mọi trường hợp. Mỗi mô hình đều mang trong mình trade-off riêng, và bài này sẽ giúp ta so sánh để chọn đúng công cụ.
🔍 Query Languages – Khi mô hình quyết định ngôn ngữ
Chương này cũng sẽ bàn đến các ngôn ngữ cho từng mô hình dữ liệu:
- SQL, Cypher, SPARQL, Datalog: ngôn ngữ declarative
- GraphQL: ngôn ngữ dùng cho phía client
- Dataframe APIs (như Pandas, Spark): imperative, thuận tiện cho thao tác từng bước
🧠 Lưu ý: Với declarative query, bạn mô tả cái bạn muốn, chứ không cần mô tả cách thực thi. Điều này cho phép tối ưu hóa tự động, song song hóa… mà không thay đổi câu truy vấn.
✅ Ghi chú nhanh:
- Declarative: tập trung vào cái bạn muốn
- Imperative: tập trung vào làm thế nào để đạt được
- Câu query declarative có thể được parallel hóa bởi database engine mà bạn không cần can thiệp
| Mô hình | Query Language | Tính chất chính |
| Relational | SQL | Declarative, hỗ trợ join, aggregate mạnh mẽ |
| Document | Mongo Aggregation, JSONPath | Khá declarative nhưng hạn chế join |
| Graph (property) | Cypher, PGQL, GQL | Pattern matching dạng biểu đồ, query đệ quy tốt |
| Graph (triple) | SPARQL | Dựa trên RDF triples, phù hợp linked data |
| Datalog | Datalog Rules | Logic-based, cực mạnh với query đệ quy |
| Event log | Không có (query view) | Cần precompute hoặc stream processing |
| Dataframe | Pandas, Spark | Imperative, scriptable, thuận cho data wrangling |
📌 Ví dụ LinkedIn Profile

Cách dùng Relational Schema (Hình 3-1):
- Dữ liệu như positions, education, contact_info được lưu ở các bảng riêng, có khoá ngoại trỏ về bảng
users.
Cách dùng JSON Document (Ví dụ 3-1):
{
"user_id": 251,
"first_name": "Barack",
"last_name": "Obama",
"headline": "Former President of the United States of America",
"region_id": "us:91",
"positions": [
{"job_title": "President", "organization": "United States of America"},
{"job_title": "US Senator (D-IL)", "organization": "United States Senate"}
],
"education": [
{"school_name": "Harvard University", "start": 1988, "end": 1991},
{"school_name": "Columbia University", "start": 1981, "end": 1983}
],
"contact_info": {
"website": "https://barackobama.com",
"twitter": "https://twitter.com/barackobama"
}
}
🌳 Cấu trúc dạng cây (tree structure)
→ JSON biểu diễn rõ cấu trúc one-to-many như positions, education, contact_info.
→ Document Model cho phép nhúng dữ liệu con trực tiếp → truy vấn nhanh hơn nếu cần lấy toàn bộ profile.
🏗️ Normalization vs. Denormalization
- 🔗 Normalized (dùng ID, join):
- ✔ Tiết kiệm storage, dễ update, consistency cao
- ❌ Truy vấn chậm hơn (cần join nhiều)
- 📦 Denormalized (dùng text trực tiếp, lặp thông tin):
- ✔ Truy vấn nhanh hơn (ít join), đơn giản hóa schema
- ❌ Tốn storage, phức tạp khi update nhiều nơi
→ OLTP → Normalized; Analytics → Denormalized.
📦 Case Study: Twitter (X) – Denormalization ở scale lớn
- Trong hệ thống timeline của Twitter:
- Mỗi dòng trạng thái là materialized view.
- Thay vì JOIN giữa
postsvàfollows, hệ thống sẽ “fan-out” post mới tới tất cả người theo dõi người đăng.
🧠 Nhưng… Họ không lưu text bài viết ngay trong timeline!
➡️ Timeline chỉ lưu:
(posts.id, posts.sender_id, ... thêm vài metadata)→ Khi người dùng mở app, hệ thống hydrate dữ liệu: tra ID bài viết để lấy nội dung, lượt like, ảnh đại diện…
💡 Vì sao không lưu text?
- Bài viết thay đổi liên tục: số like tăng giảm mỗi giây.
- Avatar người dùng hay thay đổi. → Denormalize những dữ liệu đó vào timeline sẽ tốn bộ nhớ và hiển thị không đúng thông tin mới nhất.
🧬 Graph Data Models – Khi mọi thứ liên kết với nhau
Khi hệ thống có nhiều mối liên kết phức tạp:
- Người – bạn bè – bài đăng – hashtag – vị trí – phản ứng…
- Graph phù hợp với use case xã hội, knowledge graph, recommender…
Ngôn ngữ như Cypher, SPARQL, Datalog cho phép diễn tả đệ quy rất gọn gàng.
🌟 SPARQL – Ngôn ngữ truy vấn cho triple-store
Giống như Cypher, nhưng SPARQL được dùng với RDF, và cú pháp hơi khác:
PREFIX : <urn:example:>
SELECT ?personName WHERE {
?person :name ?personName.
?person :bornIn / :within* / :name "United States".
?person :livesIn / :within* / :name "Europe".
}
/ :within* /biểu thị truy vấn theo quan hệ nhiều bước (recursive).- SPARQL rất giống Cypher, nhưng thường được dùng trong hệ thống như Wikidata, Amazon Neptune, Apache Jena…
🧩 Datalog là gì?
- Là một ngôn ngữ truy vấn logic xuất hiện từ thập niên 1980.
- Không chỉ áp dụng cho cơ sở dữ liệu quan hệ mà còn rất mạnh khi xử lý dữ liệu đồ thị có truy vấn đệ quy.
- Một số hệ thống dùng Datalog: Datomic, LogicBlox, CozoDB, LinkedIn LIquid…
🔍 Truy vấn người di cư từ US → Europe:
migrated(PName, BornIn, LivingIn) :-
person(PersonID, PName),
born_in(PersonID, BornID),
within_recursive(BornID, BornIn),
lives_in(PersonID, LivingID),
within_recursive(LivingID, LivingIn).
us_to_europe(Person) :-
migrated(Person, "United States", "Europe").
✔ Datalog hoạt động kiểu rule chaining:
→ Xây dựng từng bước → tổ hợp → tạo bảng kết quả như us_to_europe.
🔁 So sánh các ngôn ngữ:
| Ngôn ngữ | Truy vấn đệ quy | Ưu điểm nổi bật |
|---|---|---|
| SQL | Có (WITH RECURSIVE) nhưng rườm rà | Chuẩn công nghiệp, nhưng dài dòng |
| Cypher | Dễ viết (*0..) | Tối ưu cho đồ thị quan hệ đa chiều |
| SPARQL | Dễ biểu diễn pattern | Gần với RDF/semantic web |
| Datalog | ✅ Rất mạnh | Xây dựng rule theo kiểu logic, dễ kết hợp |
🌐 GraphQL là gì?
- Là một ngôn ngữ truy vấn do Facebook phát triển, giúp client (như ứng dụng di động/web) yêu cầu các trường dữ liệu cần thiết, trực tiếp từ server dưới dạng JSON.
- Không giống SQL hay Cypher, GraphQL không phải để phân tích dữ liệu, mà để lấy đúng và đủ dữ liệu hiển thị lên UI.
📋 Ví dụ: Truy vấn nhóm chat (giống Slack, Discord):
query ChatApp {
channels {
name
recentMessages(latest: 50) {
timestamp
content
sender {
fullName
imageUrl
}
replyTo {
content
sender {
fullName
}
}
}
}
}
✔ Truy vấn này yêu cầu:
- Tên các kênh (
channels.name) - 50 tin nhắn gần nhất với các trường con như người gửi, ảnh đại diện, và nếu là phản hồi thì có thêm nội dung và người được phản hồi.
🧾 JSON trả về có cấu trúc giống hệt truy vấn:
jsonCopyEdit{
"data": {
"channels": [
{
"name": "#general",
"recentMessages": [
{
"timestamp": 1693143014,
"content": "Hey! How are y'all doing?",
"sender": {
"fullName": "Aaliyah",
"imageUrl": "https://..."
},
"replyTo": null
},
...
]
}
]
}
}
📌 Điều này giúp client render UI cực nhanh và dễ, không cần thao tác dữ liệu thêm.
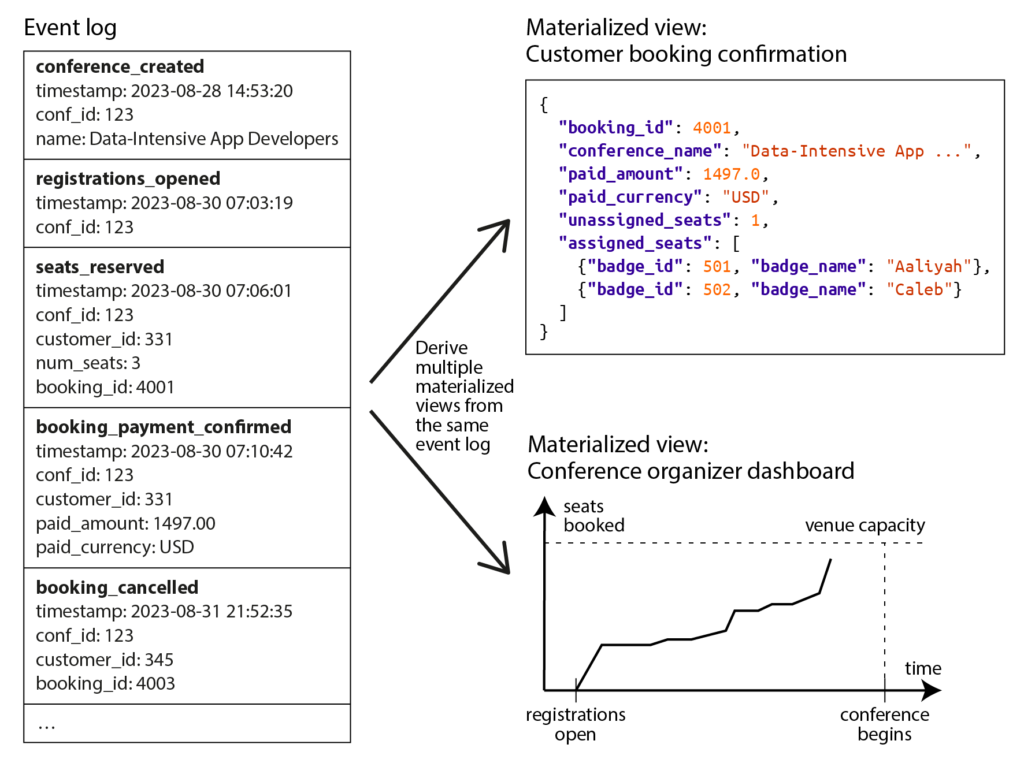
🧾 Event Sourcing & CQRS – Tách ghi và đọc
- Ghi dưới dạng log event bất biến (immutable), ví dụ:
BookingCreated,SeatCancelled. - Tạo các view đọc được cập nhật từ event.
- ✅ Dễ tracking, audit, rollback, mở rộng view mới.
- ❌ Phức tạp hơn, cần đảm bảo order của event và tránh side-effect khi rebuild.
🧪 Dataframe, Matrix, Array – Dành cho phân tích và ML
👉 Dataframe là mô hình dữ liệu được hỗ trợ bởi các hệ thống như ngôn ngữ R, thư viện Pandas trong Python, Apache Spark, ArcticDB, Dask… Đây là công cụ phổ biến cho các nhà khoa học dữ liệu dùng để chuẩn bị dữ liệu huấn luyện mô hình machine learning, nhưng cũng rất hữu ích trong việc khám phá dữ liệu, phân tích thống kê, trực quan hóa dữ liệu và các mục đích tương tự.
👀 Thoạt nhìn, dataframe trông giống như bảng trong cơ sở dữ liệu quan hệ hoặc một bảng tính (spreadsheet). Nó hỗ trợ các phép toán giống như SQL để xử lý hàng loạt dữ liệu:
- áp dụng hàm cho toàn bộ hàng,
- lọc hàng theo điều kiện,
- nhóm hàng theo cột và tổng hợp dữ liệu,
- hoặc nối (join/merge) giữa hai dataframe dựa trên một khóa nhất định.
📜 Thay vì dùng câu lệnh truy vấn kiểu khai báo như SQL, dataframe thường được xử lý thông qua một chuỗi các lệnh thao tác từng bước để thay đổi cấu trúc và nội dung dữ liệu. Điều này rất phù hợp với cách làm việc của data scientist, khi họ từng bước “nắn chỉnh” (wrangle) dữ liệu về dạng có thể giúp họ trả lời các câu hỏi phân tích. Quá trình này thường được thực hiện trên bản sao cá nhân của tập dữ liệu, đôi khi trên máy cá nhân, và kết quả có thể chia sẻ cho người khác sau đó.
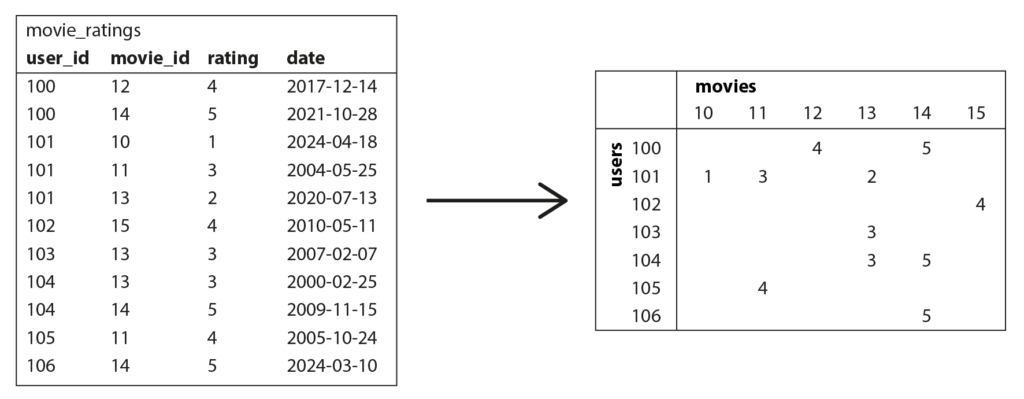
- Dataframe: bảng dữ liệu có nhiều cột (ngay cả hàng ngàn cột).
- Chuyển đổi từ bảng → ma trận cho mô hình ML.
- Có thể dùng encoding: one-hot, float scale, sparse array…
- Frameworks: Pandas, Spark, TileDB, ArcticDB, NumPy.
✅ Tổng kết
Không có mô hình dữ liệu nào là tốt nhất tuyệt đối.
- 🎯 Tùy thuộc mục tiêu: transactional? analytics? recommendation? ML?
- 🛠️ Tùy công cụ hỗ trợ và hệ sinh thái đi kèm
- 🔁 Tùy vào mức độ thay đổi dữ liệu (schema evolution, auditability…)
Tư duy mô hình dữ liệu là trái tim của kiến trúc hệ thống. Khi hiểu rõ điểm mạnh – yếu của từng mô hình, ta sẽ đưa ra các quyết định đúng đắn và bền vững hơn.
Để lại một bình luận
Bạn phải đăng nhập để gửi bình luận.