
DDD, Hexagonal, Onion, Clean, CQRS, … How I put it all together – @hgraca (herbertograca.com)
Bài viết này nằm trong loạt The Software Architecture Chronicles, một chuỗi nội dung về Kiến trúc phần mềm. Nội dung có thể dễ hiểu hơn nếu bạn đọc các phần trước trong loạt bài này.
Tôi đã từng theo nghề giáo viên trung học trước khi quyết định chuyển hẳn sang làm lập trình viên phần mềm toàn thời gian. Từ đó, tôi luôn có cảm giác cần phải bù đắp “quãng thời gian đã mất” và học hỏi càng nhiều càng tốt, càng nhanh càng tốt. Vì vậy, tôi trở nên “nghiện” việc thử nghiệm, đọc và viết, đặc biệt tập trung vào thiết kế và kiến trúc phần mềm. Đó là lý do tôi viết những bài này – để tự học.
Trong những bài viết trước, tôi đã bàn đến nhiều khái niệm và nguyên tắc, cũng như cách tôi lý giải chúng. Nhưng tất cả chỉ mới là những mảnh ghép của một bức tranh lớn.
Bài viết hôm nay nói về cách tôi ghép chúng lại thành một bức tranh hoàn chỉnh – tôi gọi nó là Explicit Architecture. Các khái niệm này không chỉ lý thuyết mà đã “qua thử lửa thực chiến” và được dùng trong code production trên những nền tảng có yêu cầu cao: ví dụ một nền tảng SaaS thương mại điện tử với hàng nghìn web-shop toàn cầu, hoặc một marketplace hoạt động ở 2 quốc gia, xử lý hơn 20 triệu message mỗi tháng qua message bus.
Các khối cơ bản của hệ thống
- Công cụ (Tools)
- Kết nối công cụ & cơ chế truyền tải đến Application Core
- Ports
- Adapter sơ cấp (Primary/Driving Adapters)
- Adapter thứ cấp (Secondary/Driven Adapters)
- Inversion of Control
- Tổ chức Application Core
- Application Layer
- Domain Layer
- Domain Services
- Domain Model
- Các Component
- Tách rời các Component
- Gọi logic từ Component khác
- Lấy dữ liệu từ Component khác
- Chia sẻ dữ liệu giữa các Component
- Dữ liệu tách riêng cho từng Component
- Luồng điều khiển (Flow of Control)
Các khối cơ bản
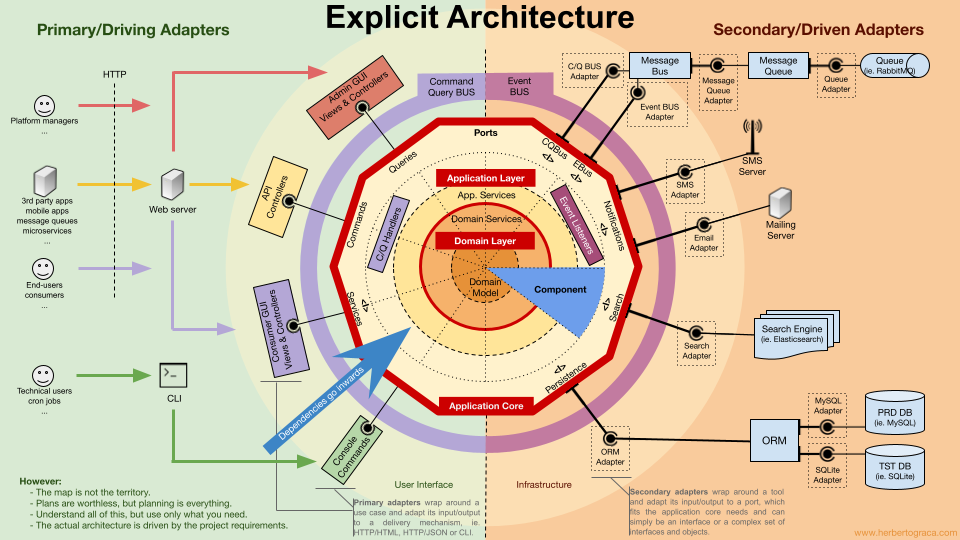
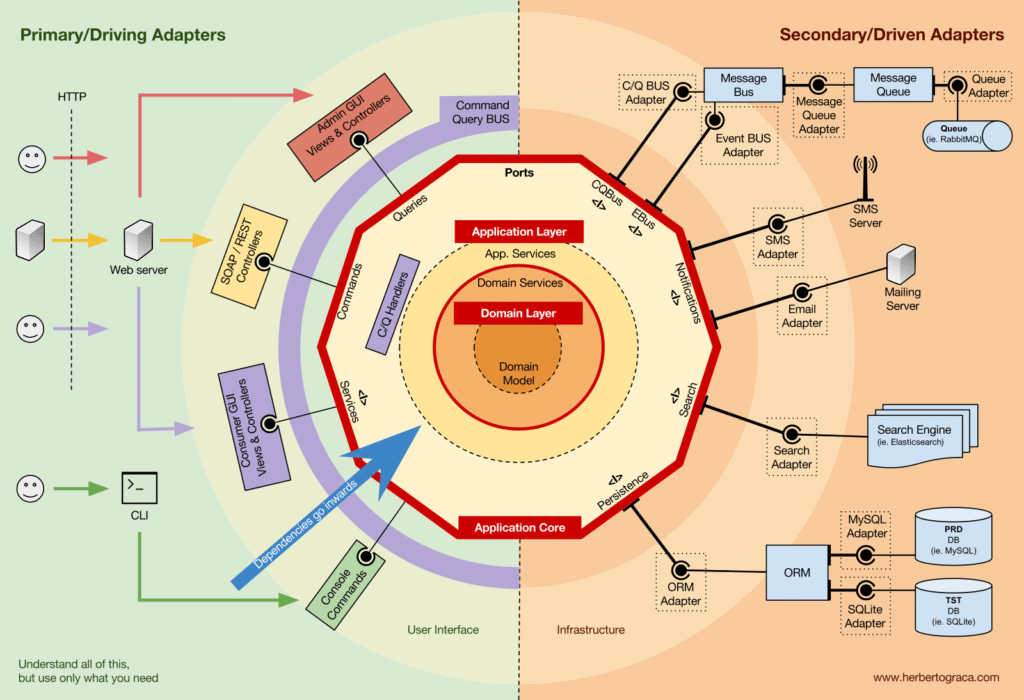
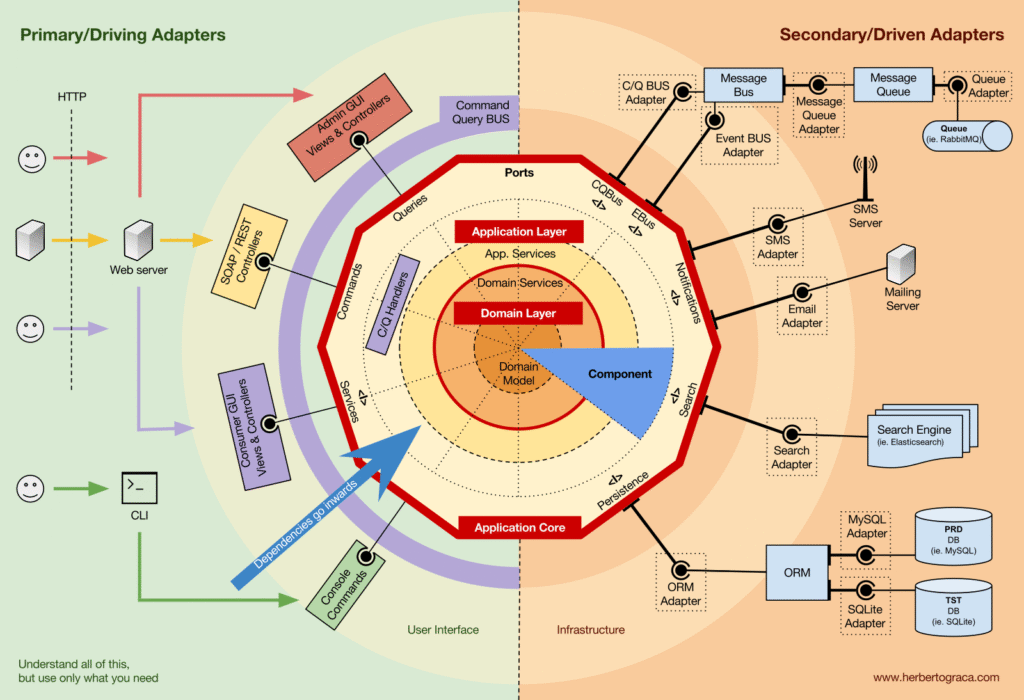
Kiến trúc EBI và Ports & Adapters tách biệt rõ ràng giữa:
- Code nội bộ ứng dụng
- Code bên ngoài
- Code kết nối nội bộ và bên ngoài
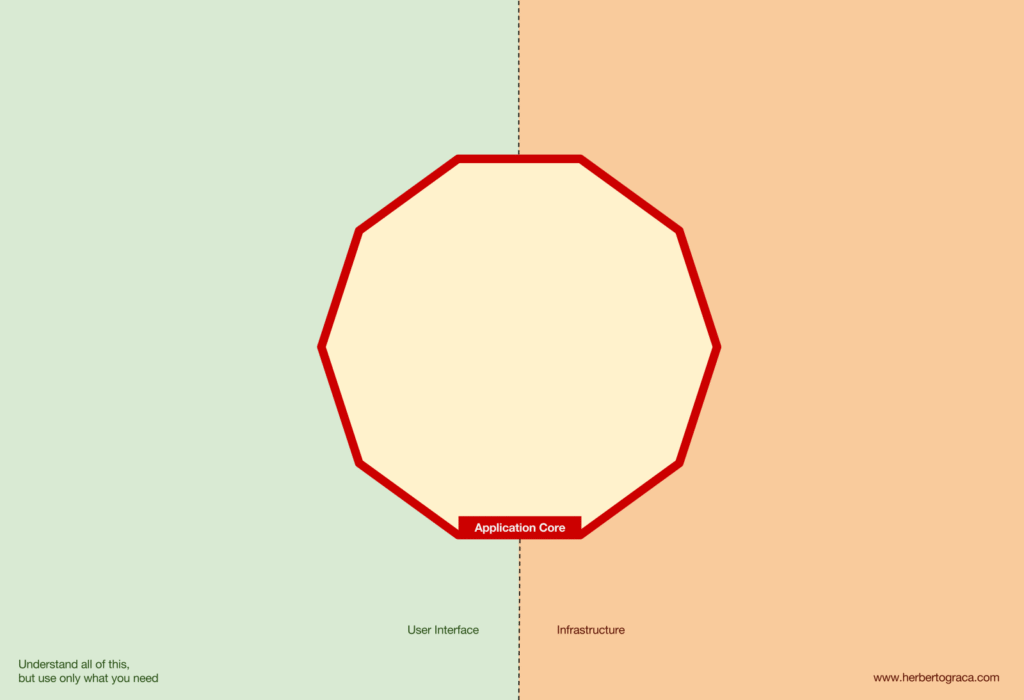
Trong đó, Ports & Adapters chỉ ra 3 khối cơ bản:
- Giao diện người dùng (UI)
- Business logic (Application Core)
- Infrastructure code (kết nối DB, search engine, API bên thứ ba…)
Application Core chính là phần quan trọng nhất, nơi chứa logic nghiệp vụ thực sự. UI có thể khác nhau (PWA, Mobile, CLI, API…) nhưng logic thực thi là một.
Luồng điển hình: UI → Application Core → Infrastructure → Application Core → UI.
Tools
Các công cụ như database engine, search engine, web server, CLI… đều là tools.
Điểm khác biệt quan trọng:
- CLI/web server ra lệnh cho app làm gì
- Database engine nhận lệnh từ app
Điều này quyết định cách ta viết code kết nối.
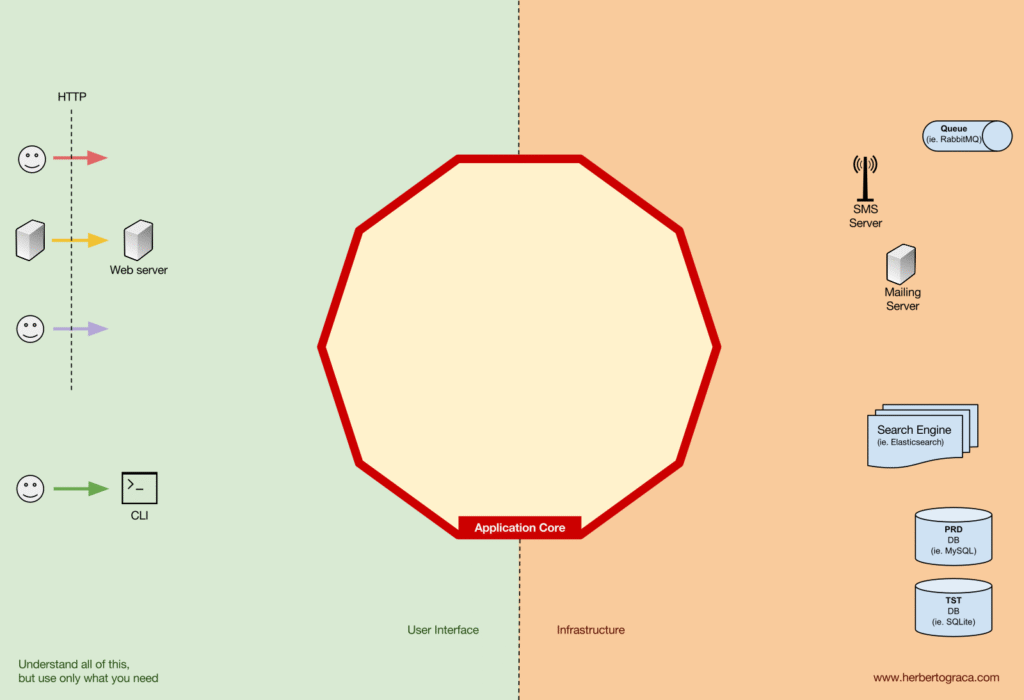
Mặc dù việc đặt một bảng điều khiển CLI vào cùng một “bucket” với một công cụ cơ sở dữ liệu có thể hơi kỳ lạ, và mặc dù chúng có các loại mục đích khác nhau, nhưng thực tế chúng là những công cụ được ứng dụng sử dụng. Điểm khác biệt chính là, trong khi bảng điều khiển CLI và máy chủ web được sử dụng để ra lệnh cho ứng dụng thực hiện một hành động nào đó, thì công cụ cơ sở dữ liệu lại được ứng dụng ra lệnh thực hiện. Đây là một sự khác biệt rất quan trọng, vì nó có ý nghĩa quan trọng đối với cách chúng ta xây dựng mã kết nối các công cụ đó với lõi ứng dụng.
Kết nối Tools & Delivery đến Application Core
- Adapter: kết nối giữa core và tool.
- Driving Adapter (Primary): ra lệnh cho core.
- Driven Adapter (Secondary): nhận lệnh từ core.
- Ports: điểm vào/ra của core, thường là Interface. Port thuộc business logic, adapter nằm ngoài.
Primary Adapters
Driving Adapters bọc quanh Port, dịch tín hiệu từ UI/delivery thành method call vào core. Ví dụ: Controller, Console Command.
Có thể nhận Service, Repository hoặc Command/Query Bus thông qua injection.
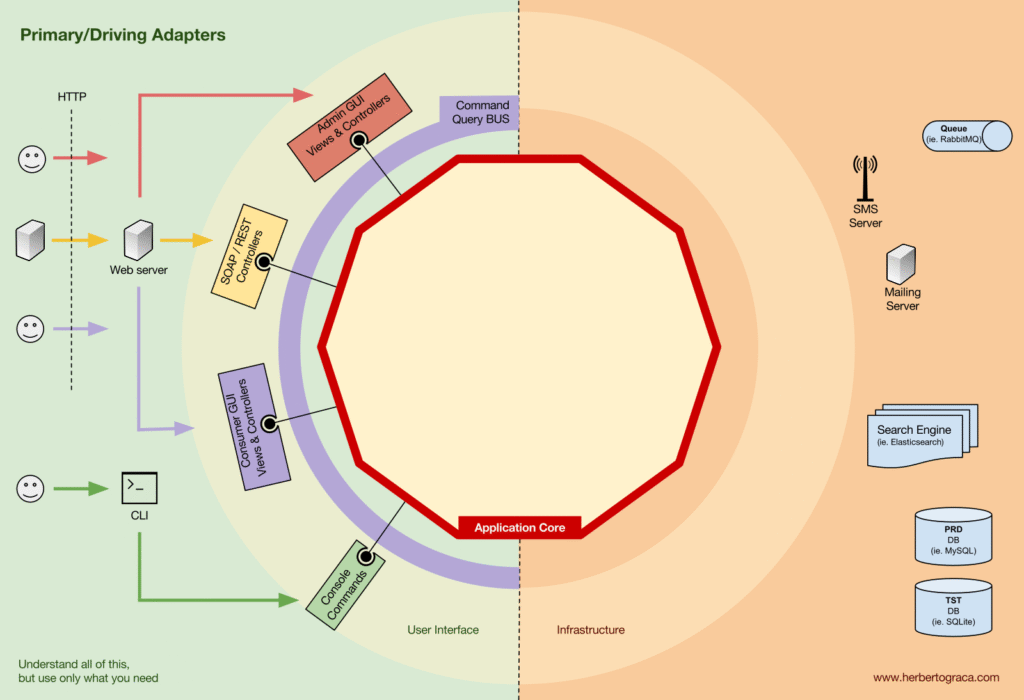
Nói cách khác, Driving Adapter của chúng ta là các Controller hoặc Console Command được inject vào constructor của chúng một số đối tượng có lớp triển khai giao diện (Port) mà controller hoặc console command yêu cầu.
Một ví dụ cụ thể hơn, Port có thể là giao diện Service hoặc giao diện Repository mà controller yêu cầu. Triển khai cụ thể của Service, Repository hoặc Query sau đó được inject và sử dụng trong Controller.
Ngoài ra, Port có thể là giao diện Command Bus hoặc Query Bus. Trong trường hợp này, một triển khai cụ thể của Command Bus hoặc Query Bus được inject vào Controller, sau đó Controller sẽ xây dựng Command hoặc Query và truyền nó đến Bus tương ứng.
Secondary Adapters
Driven Adapters implement Port và được inject vào core.
Ví dụ, giả sử chúng ta có một ứng dụng đơn giản cần lưu trữ dữ liệu. Vì vậy, chúng ta tạo một giao diện lưu trữ đáp ứng nhu cầu của ứng dụng, với một phương thức để lưu một mảng dữ liệu và một phương thức để xóa một dòng trong bảng theo ID của nó. Từ đó trở đi, bất cứ khi nào ứng dụng cần lưu hoặc xóa dữ liệu, chúng ta sẽ yêu cầu trong hàm khởi tạo của nó một đối tượng triển khai giao diện lưu trữ đã định nghĩa.
Bây giờ, chúng ta tạo một bộ điều hợp dành riêng cho MySQL để triển khai giao diện đó. Nó sẽ có các phương thức để lưu một mảng và xóa một dòng trong bảng, và chúng ta sẽ inject nó vào bất cứ nơi nào cần giao diện lưu trữ.
Nếu tại một thời điểm nào đó, chúng ta quyết định thay đổi nhà cung cấp cơ sở dữ liệu, chẳng hạn như PostgreSQL hoặc MongoDB, chúng ta chỉ cần tạo một bộ điều hợp mới triển khai giao diện lưu trữ và dành riêng cho PostgreSQL, và inject bộ điều hợp mới thay vì bộ điều hợp cũ.
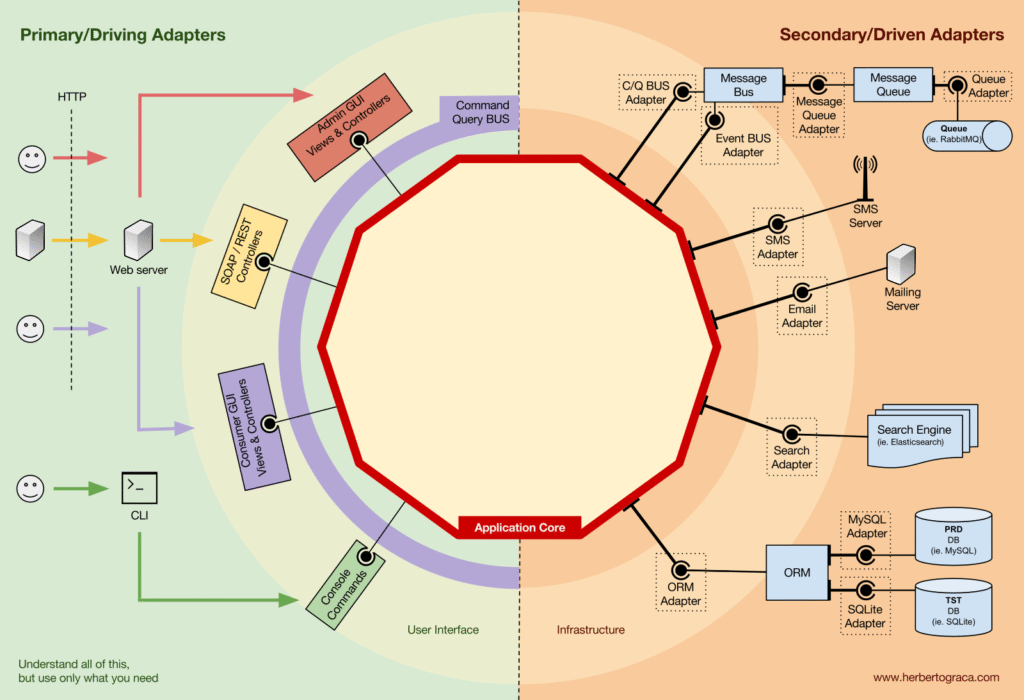
Inversion of Control
Một đặc điểm cần lưu ý về mô hình này là các bộ điều hợp phụ thuộc vào một công cụ và một cổng cụ thể (bằng cách triển khai một giao diện). Tuy nhiên, logic nghiệp vụ của chúng ta chỉ phụ thuộc vào cổng (giao diện), được thiết kế để phù hợp với nhu cầu logic nghiệp vụ, vì vậy nó không phụ thuộc vào một bộ điều hợp hoặc công cụ cụ thể nào.
Điều này có nghĩa là hướng của các phụ thuộc hướng về trung tâm, đó là nguyên lý đảo ngược điều khiển ở cấp độ kiến trúc.
Tuy nhiên, một lần nữa, điều tối quan trọng là các Cổng được tạo ra để phù hợp với nhu cầu của Lõi Ứng dụng chứ không chỉ đơn thuần là mô phỏng các API của công cụ.
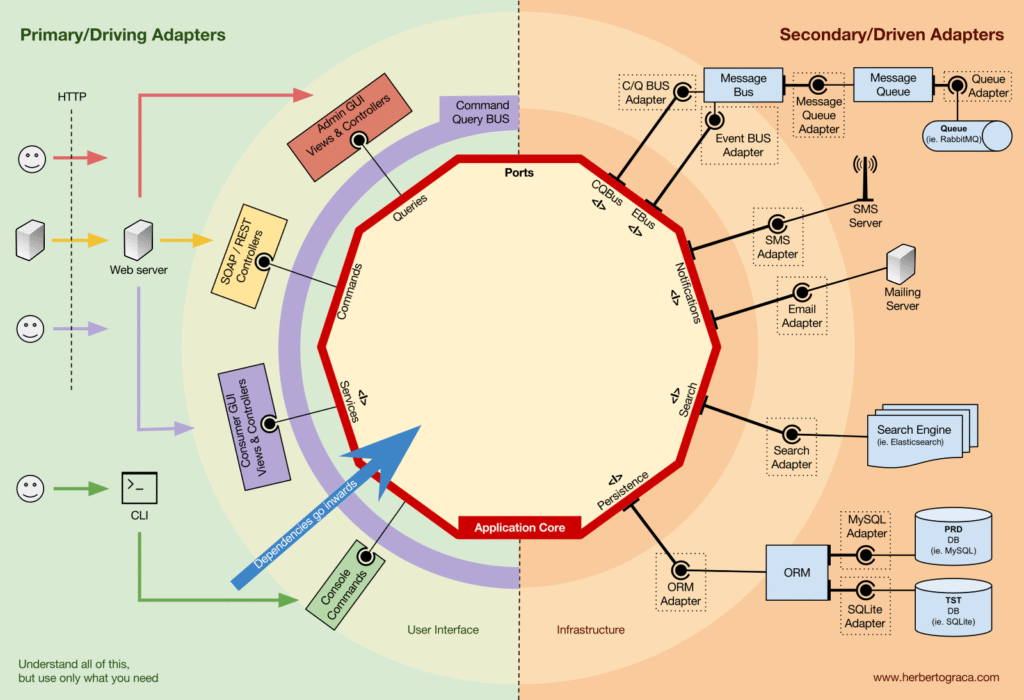
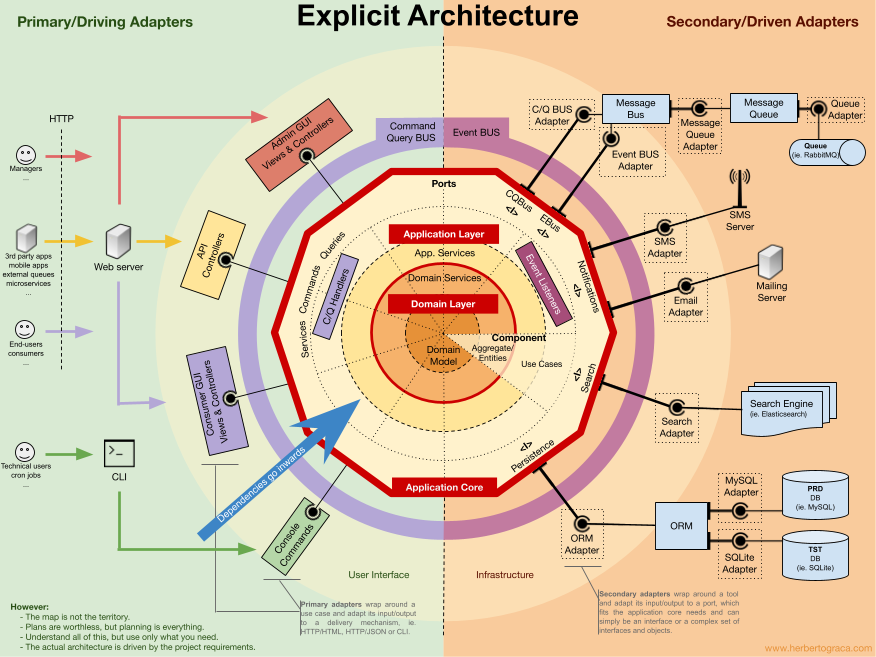
Application Core Organisation
Kiến trúc Onion tiếp nhận các lớp DDD và tích hợp chúng vào Kiến trúc Cổng & Bộ điều hợp. Các lớp này nhằm mục đích mang lại sự tổ chức cho logic nghiệp vụ, phần bên trong của “hình lục giác” Cổng & Bộ điều hợp, và giống như trong Cổng & Bộ điều hợp, hướng phụ thuộc hướng về trung tâm.
Application Layer
Chứa Use Case và Application Services.
Có thể có nhiều UI (CMS, Admin UI, CLI, API) → đều gọi Use Case.
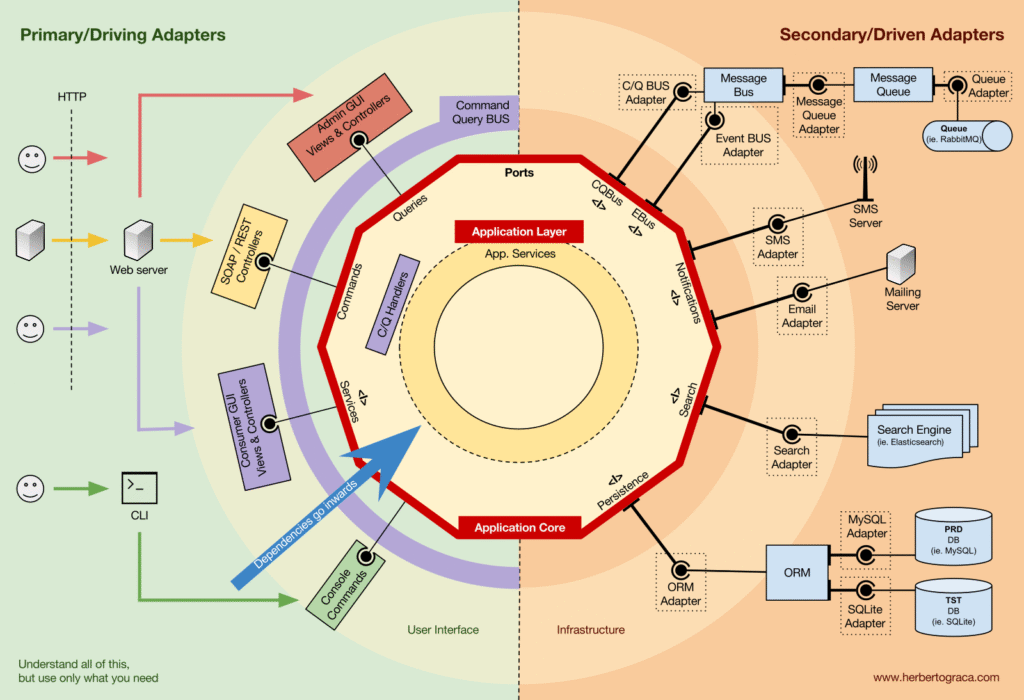
Use Case thường:
- Dùng Repository để lấy Entities
- Gọi logic trong Entity
- Lưu lại qua Repository
Trình xử lý lệnh có thể được sử dụng theo hai cách khác nhau:
Chúng có thể chứa logic thực tế để thực hiện trường hợp sử dụng;
Chúng có thể được sử dụng như những phần nối dây đơn thuần trong kiến trúc của chúng ta, nhận lệnh và chỉ đơn giản là kích hoạt logic tồn tại trong Dịch vụ ứng dụng.
Cách tiếp cận sử dụng tùy thuộc vào ngữ cảnh, ví dụ:
Chúng ta đã có Dịch vụ ứng dụng và hiện đang thêm một Bus lệnh?
Bus lệnh có cho phép chỉ định bất kỳ lớp/phương thức nào làm trình xử lý hay chúng cần mở rộng hoặc triển khai các lớp hoặc giao diện hiện có?
Lớp này cũng chứa chức năng kích hoạt Sự kiện ứng dụng, đại diện cho một số kết quả của một trường hợp sử dụng. Các sự kiện này kích hoạt logic là một tác dụng phụ của một trường hợp sử dụng, chẳng hạn như gửi email, thông báo cho API của bên thứ ba, gửi thông báo đẩy hoặc thậm chí bắt đầu một trường hợp sử dụng khác thuộc một thành phần khác của ứng dụng.
Domain Layer
Chứa dữ liệu + logic xử lý dữ liệu thuần domain, độc lập với Application Layer.
- Domain Services: khi logic liên quan nhiều Entity, không nên đặt trong Application Service → tách thành Domain Service.
- Domain Model: lõi trung tâm, gồm Entities, Value Objects, Enums, Domain Events.
Như tôi đã đề cập ở trên, vai trò của một Dịch vụ Ứng dụng là:
- Sử dụng một kho lưu trữ để tìm một hoặc nhiều thực thể;
- Yêu cầu các thực thể đó thực hiện một số logic miền;
- Và sử dụng kho lưu trữ để lưu trữ lại các thực thể, giúp lưu trữ các thay đổi dữ liệu một cách hiệu quả.
Tuy nhiên, đôi khi chúng ta gặp phải một số logic miền liên quan đến các thực thể khác nhau, cùng loại hoặc khác loại, và chúng ta cảm thấy logic miền đó không thuộc về chính các thực thể đó, chúng ta cảm thấy logic đó không phải là trách nhiệm trực tiếp của chúng.
Vì vậy, phản ứng đầu tiên của chúng ta có thể là đặt logic đó bên ngoài các thực thể, trong một Dịch vụ Ứng dụng. Tuy nhiên, điều này có nghĩa là logic miền đó sẽ không thể tái sử dụng trong các trường hợp sử dụng khác: logic miền nên nằm ngoài lớp ứng dụng!
Giải pháp là tạo một Dịch vụ Miền, có vai trò tiếp nhận một tập hợp các thực thể và thực hiện một số logic nghiệp vụ trên chúng. Dịch vụ Miền thuộc về Lớp Miền, và do đó nó không biết gì về các lớp trong Lớp Ứng dụng, chẳng hạn như Dịch vụ Ứng dụng hoặc Kho lưu trữ. Mặt khác, nó có thể sử dụng các Dịch vụ Miền khác và tất nhiên là các đối tượng Mô hình Miền.
Components
Ngoài phân tầng mịn (layer), cần phân tách thô (component) theo sub-domain / bounded context.
Ví dụ: Authentication, Authorization, Billing, User, Review, Account.
Mỗi component là một đơn vị độc lập, ít coupling, cohesion cao.
Cho đến nay, chúng ta đã phân tách mã dựa trên các lớp, nhưng đó là phân tách mã chi tiết. Phân tách mã chi tiết cũng quan trọng không kém, ít nhất là không kém, và nó liên quan đến việc phân tách mã theo các miền con và ngữ cảnh bị giới hạn, theo ý tưởng của Robert C. Martin được thể hiện trong kiến trúc “screaming architecture”. Điều này thường được gọi là “Gói theo tính năng” hoặc “Gói theo thành phần” thay vì “Gói theo lớp”, và điều này đã được Simon Brown giải thích khá rõ trong bài đăng trên blog của ông “Gói theo thành phần và kiểm thử theo kiến trúc”:
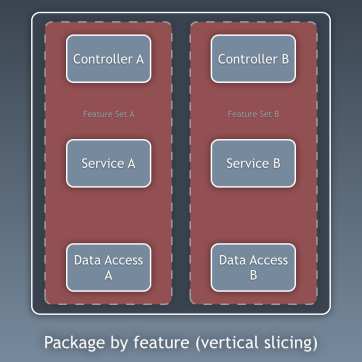
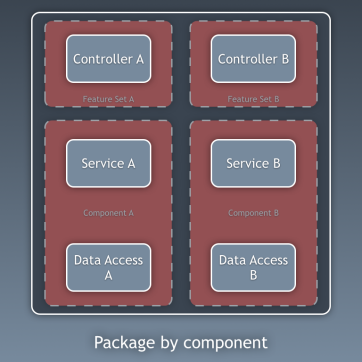
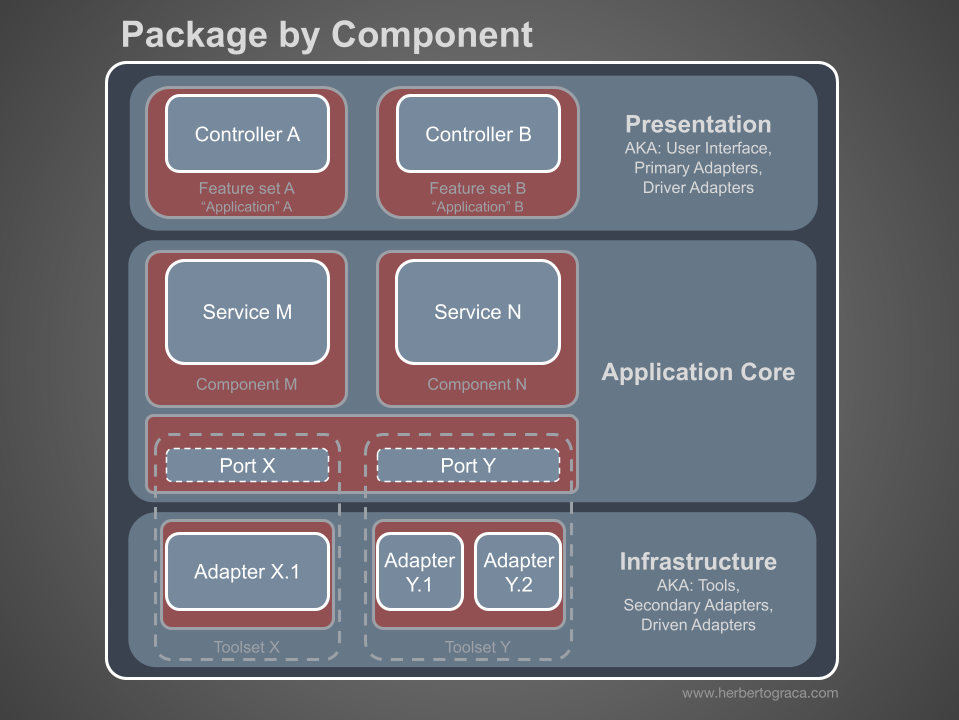
Các đoạn mã này liên quan đến các lớp đã mô tả trước đó, chúng là các thành phần của ứng dụng. Ví dụ về các thành phần có thể là Xác thực, Ủy quyền, Thanh toán, Người dùng, Đánh giá hoặc Tài khoản, nhưng chúng luôn liên quan đến miền. Các ngữ cảnh bị ràng buộc như Ủy quyền và/hoặc Xác thực nên được xem như các công cụ bên ngoài mà chúng ta tạo một bộ điều hợp và ẩn sau một loại cổng nào đó.
Decoupling the components
Cũng giống như các đơn vị mã chi tiết (lớp, giao diện, đặc điểm, mixin,…), các đơn vị mã chi tiết (thành phần) cũng được hưởng lợi từ sự liên kết thấp và tính gắn kết cao.
Để tách các lớp, chúng ta sử dụng Dependency Injection (Tiêm phụ thuộc), bằng cách tiêm các phụ thuộc vào một lớp thay vì khởi tạo chúng bên trong lớp, và Dependency Inversion (Đảo ngược phụ thuộc), bằng cách khiến lớp phụ thuộc vào các lớp trừu tượng (giao diện và/hoặc lớp trừu tượng) thay vì các lớp cụ thể. Điều này có nghĩa là lớp phụ thuộc không có kiến thức về lớp cụ thể mà nó sẽ sử dụng, nó không có tham chiếu đến tên lớp đầy đủ của các lớp mà nó phụ thuộc vào.
Tương tự như vậy, việc có các thành phần được tách rời hoàn toàn có nghĩa là một thành phần không có kiến thức trực tiếp về bất kỳ thành phần nào khác. Nói cách khác, nó không có tham chiếu đến bất kỳ đơn vị mã chi tiết nào từ một thành phần khác, ngay cả giao diện! Điều này có nghĩa là Dependency Injection và Dependency Inversion là không đủ để tách các thành phần, chúng ta sẽ cần một số loại cấu trúc kiến trúc. Chúng ta có thể cần các sự kiện, một hạt nhân được chia sẻ, tính nhất quán cuối cùng và thậm chí là một dịch vụ khám phá!
Logic kích hoạt trong các thành phần khác
Khi một trong các thành phần của chúng ta (thành phần B) cần thực hiện một hành động nào đó bất cứ khi nào có hành động khác xảy ra trong một thành phần khác (thành phần A), chúng ta không thể chỉ cần gọi trực tiếp từ thành phần A đến một lớp/phương thức trong thành phần B vì khi đó A sẽ được kết nối với B.
Tuy nhiên, chúng ta có thể yêu cầu A sử dụng một bộ phân phối sự kiện để phân phối một sự kiện ứng dụng, sự kiện này sẽ được gửi đến bất kỳ thành phần nào đang lắng nghe nó, bao gồm cả B, và bộ lắng nghe sự kiện trong B sẽ kích hoạt hành động mong muốn. Điều này có nghĩa là thành phần A sẽ phụ thuộc vào một bộ phân phối sự kiện, nhưng nó sẽ được tách rời khỏi B.
Tuy nhiên, nếu bản thân sự kiện “tồn tại” trong A, điều này có nghĩa là B biết về sự tồn tại của A, nó được kết nối với A. Để loại bỏ sự phụ thuộc này, chúng ta có thể tạo một thư viện với một tập hợp các chức năng cốt lõi của ứng dụng sẽ được chia sẻ giữa tất cả các thành phần, được gọi là Hạt nhân Chia sẻ. Điều này có nghĩa là các thành phần sẽ đều phụ thuộc vào Hạt nhân Chia sẻ nhưng chúng sẽ được tách rời khỏi nhau. Hạt nhân được chia sẻ sẽ chứa các chức năng như sự kiện ứng dụng và miền, nhưng nó cũng có thể chứa các đối tượng Đặc tả và bất kỳ thứ gì có ý nghĩa để chia sẻ, lưu ý rằng nó phải càng tối thiểu càng tốt vì bất kỳ thay đổi nào đối với Hạt nhân được chia sẻ sẽ ảnh hưởng đến tất cả các thành phần của ứng dụng. Hơn nữa, nếu chúng ta có một hệ thống đa ngôn ngữ, giả sử là một hệ sinh thái dịch vụ vi mô trong đó chúng được viết bằng các ngôn ngữ khác nhau, thì Hạt nhân được chia sẻ cần phải không phụ thuộc vào ngôn ngữ để tất cả các thành phần có thể hiểu được, bất kể chúng được viết bằng ngôn ngữ nào. Ví dụ: thay vì Hạt nhân được chia sẻ chứa một lớp Sự kiện, nó sẽ chứa mô tả sự kiện (tức là tên, thuộc tính, thậm chí có thể là các phương thức mặc dù những thứ này sẽ hữu ích hơn trong một đối tượng Đặc tả) bằng một ngôn ngữ không phụ thuộc như JSON, để tất cả các thành phần/dịch vụ vi mô có thể diễn giải nó và thậm chí có thể tự động tạo các triển khai cụ thể của riêng chúng. Đọc thêm về điều này trong bài đăng tiếp theo của tôi: Nhiều hơn các lớp đồng tâm.
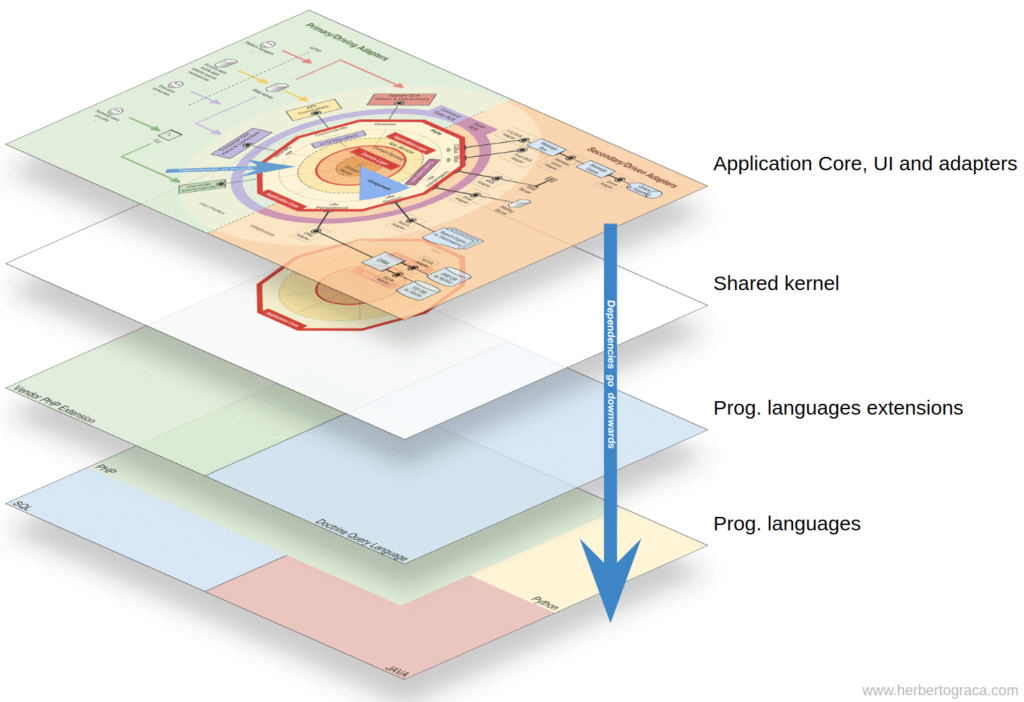
Cách tiếp cận này hoạt động trong cả ứng dụng đơn khối và ứng dụng phân tán như hệ sinh thái vi dịch vụ. Tuy nhiên, khi các sự kiện chỉ có thể được phân phối không đồng bộ, đối với các ngữ cảnh mà logic kích hoạt trong các thành phần khác cần được thực hiện ngay lập tức thì cách tiếp cận này sẽ không đủ! Thành phần A sẽ cần thực hiện một lệnh gọi HTTP trực tiếp đến thành phần B. Trong trường hợp này, để tách rời các thành phần, chúng ta sẽ cần một dịch vụ khám phá mà A sẽ hỏi nơi nó nên gửi yêu cầu để kích hoạt hành động mong muốn, hoặc gửi yêu cầu đến dịch vụ khám phá, dịch vụ này có thể ủy quyền yêu cầu đó cho dịch vụ liên quan và cuối cùng trả về phản hồi cho người yêu cầu. Cách tiếp cận này sẽ kết nối các thành phần với dịch vụ khám phá nhưng sẽ giữ chúng tách biệt với nhau.
Lấy dữ liệu từ các thành phần khác
Theo tôi thấy, một thành phần không được phép thay đổi dữ liệu mà nó không “sở hữu”, nhưng nó có thể truy vấn và sử dụng bất kỳ dữ liệu nào.
Lưu trữ dữ liệu được chia sẻ giữa các thành phần
Khi một thành phần cần sử dụng dữ liệu thuộc về một thành phần khác, ví dụ như thành phần thanh toán cần sử dụng tên khách hàng thuộc về thành phần tài khoản, thành phần thanh toán sẽ chứa một đối tượng truy vấn để truy vấn kho lưu trữ dữ liệu cho dữ liệu đó. Điều này đơn giản có nghĩa là thành phần thanh toán có thể biết về bất kỳ tập dữ liệu nào, nhưng nó phải sử dụng dữ liệu mà nó không “sở hữu” ở chế độ chỉ đọc, thông qua các truy vấn.
Lưu trữ dữ liệu được phân tách theo từng thành phần
Trong trường hợp này, mô hình tương tự cũng được áp dụng, nhưng chúng ta có sự phức tạp hơn ở cấp độ lưu trữ dữ liệu. Việc có các thành phần với kho lưu trữ dữ liệu riêng có nghĩa là mỗi kho lưu trữ dữ liệu chứa:
Một tập dữ liệu mà nó sở hữu và là dữ liệu duy nhất được phép thay đổi, khiến nó trở thành nguồn dữ liệu đáng tin cậy duy nhất;
Một tập dữ liệu là bản sao của dữ liệu các thành phần khác, mà nó không thể tự thay đổi, nhưng cần thiết cho chức năng của thành phần và cần được cập nhật bất cứ khi nào dữ liệu thay đổi trong thành phần chủ sở hữu.
Mỗi thành phần sẽ tạo một bản sao cục bộ của dữ liệu mà nó cần từ các thành phần khác, để sử dụng khi cần. Khi dữ liệu trong thành phần sở hữu nó thay đổi, thành phần sở hữu đó sẽ kích hoạt một sự kiện miền mang dữ liệu thay đổi. Các thành phần lưu giữ bản sao của dữ liệu đó sẽ lắng nghe sự kiện miền đó và sẽ cập nhật bản sao cục bộ của chúng cho phù hợp.
Data Sharing
- Component chỉ đọc data của component khác, không được tự ý sửa.
- Có thể chia sẻ data:
- Shared storage (đọc read-only).
- Segregated storage (mỗi component giữ bản copy local, cập nhật qua domain events).
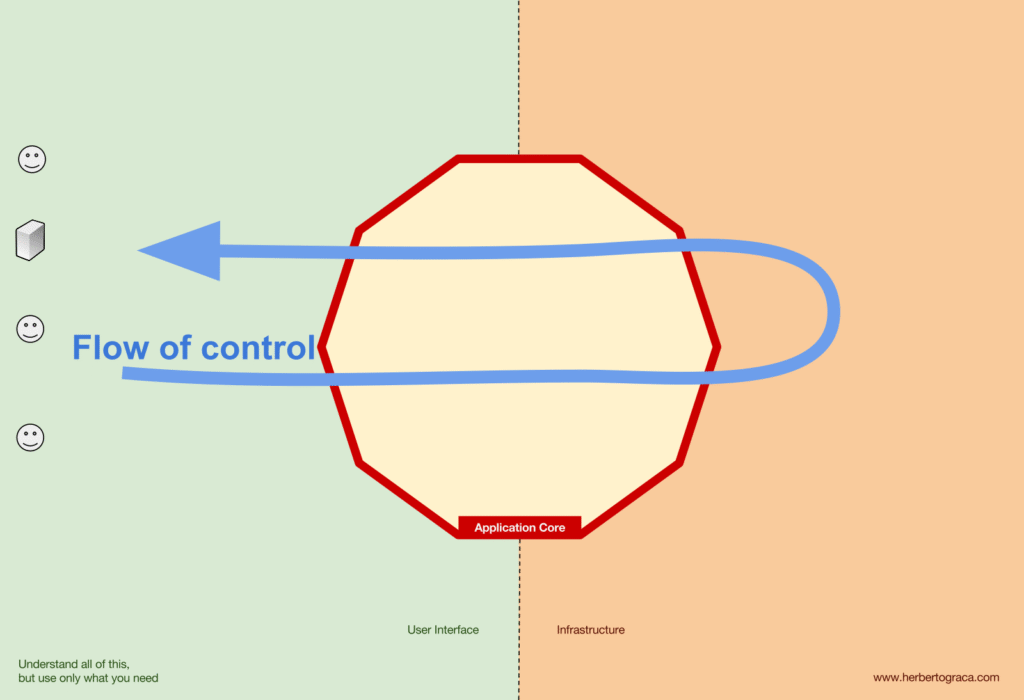
Flow of Control
Như tôi đã nói ở trên, luồng điều khiển tất nhiên đi từ người dùng vào Application Core, qua các công cụ cơ sở hạ tầng, trở lại Application Core và cuối cùng trở lại người dùng. Nhưng chính xác thì các lớp khớp với nhau như thế nào? Lớp nào phụ thuộc vào lớp nào? Chúng ta tạo thành chúng như thế nào?
Tiếp nối Uncle Bob, trong bài viết về Kiến trúc Sạch, tôi sẽ cố gắng giải thích luồng điều khiển bằng sơ đồ UMLish…
Không có Bus Lệnh/Truy vấn
Trong trường hợp chúng ta không sử dụng bus lệnh, các Bộ điều khiển sẽ phụ thuộc vào Dịch vụ Ứng dụng hoặc vào một đối tượng Truy vấn.
Tôi đã hoàn toàn bỏ lỡ DTO mà tôi sử dụng để trả về dữ liệu từ truy vấn, vì vậy tôi đã thêm nó vào bây giờ. Cảm ơn MorphineAdministered đã chỉ ra điều này cho tôi.
Luồng: UI → Core → Tools → Core → UI.
- Không dùng Command/Query Bus: Controller gọi Application Service hoặc Query → Repository → Entity → (Domain Service) → Event Dispatcher → DTO → ViewModel → View.
- Dùng Command/Query Bus: Controller gửi Command/Query qua Bus → Handler → Application Service (hoặc trực tiếp xử lý).
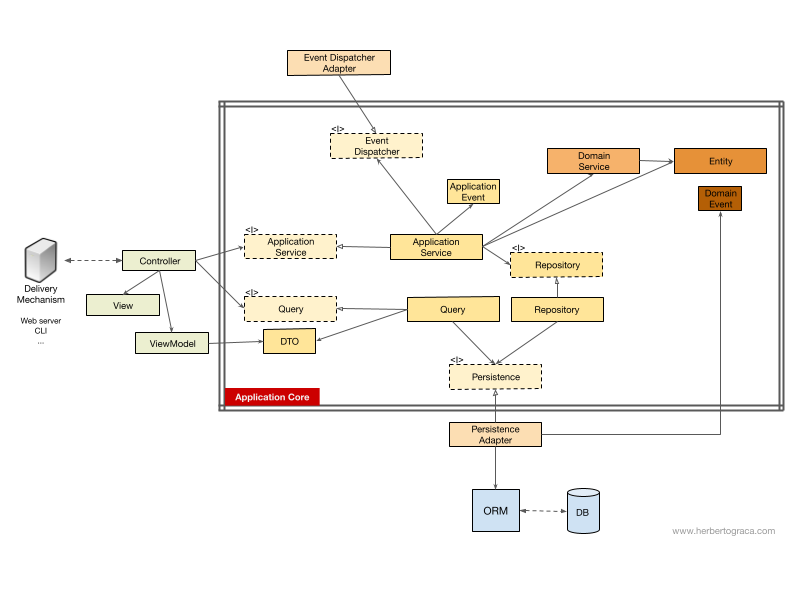
Trong sơ đồ trên, chúng ta sử dụng một giao diện cho Dịch vụ Ứng dụng, mặc dù chúng ta có thể lập luận rằng nó không thực sự cần thiết vì Dịch vụ Ứng dụng là một phần của mã ứng dụng và chúng ta sẽ không muốn hoán đổi nó cho một triển khai khác, mặc dù chúng ta có thể cấu trúc lại toàn bộ.
Đối tượng Query sẽ chứa một truy vấn được tối ưu hóa, đơn giản trả về một số dữ liệu thô để hiển thị cho người dùng. Dữ liệu đó sẽ được trả về trong một DTO, sau đó được đưa vào ViewModel. ViewModel này có thể chứa một số logic view và nó sẽ được sử dụng để điền vào View.
Mặt khác, Dịch vụ Ứng dụng sẽ chứa logic trường hợp sử dụng, logic mà chúng ta sẽ kích hoạt khi muốn thực hiện một thao tác nào đó trong hệ thống, thay vì chỉ đơn giản là xem một số dữ liệu. Dịch vụ Ứng dụng phụ thuộc vào Kho lưu trữ, kho lưu trữ này sẽ trả về (các) Thực thể chứa logic cần được kích hoạt. Nó cũng có thể phụ thuộc vào Dịch vụ Miền để điều phối một quy trình miền trong nhiều thực thể, nhưng điều đó hiếm khi xảy ra.
Sau khi triển khai use case, Application Service có thể muốn thông báo cho toàn bộ hệ thống rằng use case đó đã xảy ra, trong trường hợp đó, nó cũng sẽ phụ thuộc vào một bộ phân phối sự kiện để kích hoạt sự kiện.
Điều thú vị cần lưu ý là chúng ta đặt giao diện trên cả công cụ lưu trữ và kho lưu trữ. Mặc dù có vẻ thừa thãi, nhưng chúng phục vụ các mục đích khác nhau:
Giao diện lưu trữ là một lớp trừu tượng trên ORM, do đó chúng ta có thể hoán đổi ORM đang được sử dụng mà không cần thay đổi Application Core.
Giao diện kho lưu trữ là một lớp trừu tượng trên chính công cụ lưu trữ. Giả sử chúng ta muốn chuyển từ MySQL sang MongoDB. Giao diện lưu trữ có thể giống nhau, và nếu chúng ta muốn tiếp tục sử dụng cùng một ORM, ngay cả bộ điều hợp lưu trữ cũng sẽ giữ nguyên. Tuy nhiên, ngôn ngữ truy vấn hoàn toàn khác nhau, vì vậy chúng ta có thể tạo các kho lưu trữ mới sử dụng cùng một cơ chế lưu trữ, triển khai cùng các giao diện kho lưu trữ nhưng xây dựng các truy vấn bằng ngôn ngữ truy vấn MongoDB thay vì SQL.
Với Bus Lệnh/Truy vấn
Trong trường hợp ứng dụng của chúng ta sử dụng Bus Lệnh/Truy vấn, sơ đồ gần như giữ nguyên, ngoại trừ việc bộ điều khiển giờ đây phụ thuộc vào Bus và một lệnh hoặc một Truy vấn. Nó sẽ khởi tạo Lệnh hoặc Truy vấn và chuyển nó đến Bus, Bus sẽ tìm trình xử lý thích hợp để nhận và xử lý lệnh.
Trong sơ đồ bên dưới, Trình xử lý Lệnh sau đó sử dụng một Dịch vụ Ứng dụng. Tuy nhiên, điều đó không phải lúc nào cũng cần thiết, thực tế trong hầu hết các trường hợp, trình xử lý sẽ chứa tất cả logic của trường hợp sử dụng. Chúng ta chỉ cần trích xuất logic từ trình xử lý vào một Dịch vụ Ứng dụng riêng biệt nếu cần sử dụng lại logic đó trong một trình xử lý khác.
Tôi đã hoàn toàn bỏ lỡ DTO mà tôi sử dụng để trả về dữ liệu từ truy vấn, vì vậy tôi đã thêm nó vào đây. Cảm ơn MorphineAdministered đã chỉ ra điều này cho tôi.
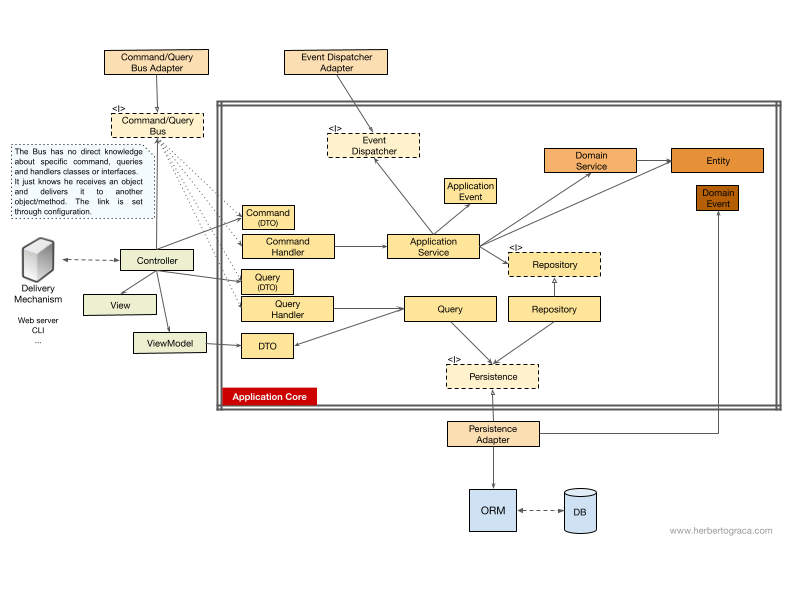
Bạn có thể nhận thấy rằng không có sự phụ thuộc nào giữa Bus và Command, Query hay Handler. Điều này là do trên thực tế, chúng không nên liên quan đến nhau để đảm bảo sự tách biệt tốt. Cách Bus biết Handler nào nên xử lý Command hay Query nào nên được thiết lập chỉ bằng cấu hình.
Như bạn có thể thấy, trong cả hai trường hợp, tất cả các mũi tên, các phụ thuộc, vượt qua ranh giới của lõi ứng dụng, đều hướng vào bên trong. Như đã giải thích trước đây, đây là một quy tắc cơ bản của Kiến trúc Cổng & Bộ điều hợp, Kiến trúc Hành và Kiến trúc Sạch.

Kết luận
Mục tiêu, như mọi khi, là có một cơ sở mã nguồn được liên kết lỏng lẻo và có tính gắn kết cao, để việc thay đổi trở nên dễ dàng, nhanh chóng và an toàn.
Kế hoạch thì vô giá trị, nhưng lập kế hoạch là tất cả. – Eisenhower
Đồ họa thông tin này là một bản đồ khái niệm. Việc biết và hiểu tất cả những khái niệm này sẽ giúp chúng ta lập kế hoạch cho một kiến trúc lành mạnh, một ứng dụng lành mạnh.
Tuy nhiên:
Bản đồ không phải là lãnh thổ. – Alfred Korzybski
Điều này chỉ mang tính chất hướng dẫn! Ứng dụng là lãnh thổ, là thực tế, là trường hợp sử dụng cụ thể mà chúng ta cần áp dụng kiến thức, và đó chính là điều sẽ xác định kiến trúc thực tế sẽ trông như thế nào!
Chúng ta cần hiểu tất cả những mô hình này, nhưng chúng ta cũng luôn cần suy nghĩ và hiểu chính xác ứng dụng của mình cần gì, chúng ta nên đi bao xa để tách rời và gắn kết. Quyết định này có thể phụ thuộc vào nhiều yếu tố, bắt đầu từ các yêu cầu chức năng của dự án, nhưng cũng có thể bao gồm các yếu tố như khung thời gian xây dựng ứng dụng, vòng đời của ứng dụng, kinh nghiệm của nhóm phát triển, v.v.
Đây là tất cả, đây là cách tôi hiểu tất cả. Đây là cách tôi lý giải nó trong đầu.
Tôi đã mở rộng những ý tưởng này thêm một chút trong bài đăng tiếp theo: Hơn cả các lớp đồng tâm.
Tuy nhiên, làm thế nào để chúng ta thể hiện rõ ràng tất cả những điều này trong cơ sở mã? Đó là chủ đề của một trong những bài đăng tiếp theo của tôi: cách phản ánh kiến trúc và miền trong mã.
Cuối cùng nhưng không kém phần quan trọng, xin cảm ơn đồng nghiệp Francesco Mastrogiacomo đã giúp tôi làm cho infographic của mình trông đẹp mắt. 🙂
Để lại một bình luận
Bạn phải đăng nhập để gửi bình luận.